Cảm biến LiDAR và Point Cloud trong xe tự lái
Trong lĩnh vực xe tự lái, cảm biến LiDAR (Light Detection And Ranging) đóng vai trò vô cùng quan trọng. LiDAR hoạt động bằng cách phát ra các tia laser và đo thời gian phản xạ để tạo ra bản đồ 3D chi tiết về môi trường xung quanh. Kết quả thu được là một đám mây điểm 3D (point cloud) - tập hợp hàng nghìn hoặc hàng triệu điểm trong không gian 3D, mỗi điểm chứa thông tin về vị trí (x, y, z) và đôi khi là cường độ phản xạ (intensity).
Point cloud từ LiDAR cung cấp thông tin hình học chính xác về môi trường, cho phép xe tự lái:
- Xác định chính xác vị trí và khoảng cách của các đối tượng
- Nhận diện hình dạng 3D của các vật thể như xe cộ, người đi bộ, và chướng ngại vật
- Hoạt động hiệu quả trong điều kiện ánh sáng khác nhau, kể cả ban đêm
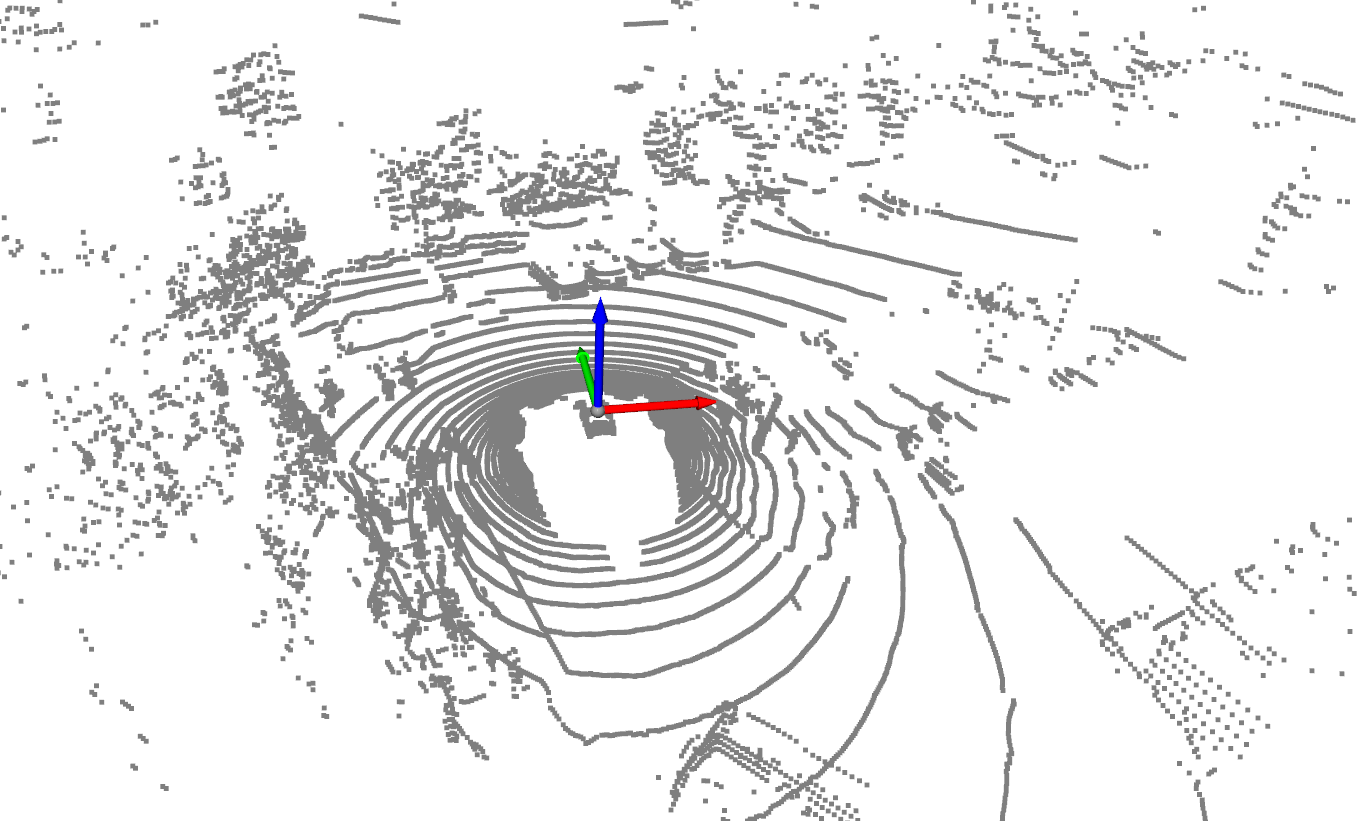
Lợi ích của Point Cloud trong phát hiện đối tượng 3D
Point cloud mang lại nhiều lợi thế trong các bài toán deep learning cho xe tự lái:
-
Thông tin không gian 3D chính xác: Khác với camera 2D, point cloud cung cấp thông tin độ sâu và vị trí chính xác, giúp dễ dàng đo lường kích thước và khoảng cách.
-
Độc lập với điều kiện ánh sáng: LiDAR hoạt động tốt trong điều kiện thiếu sáng hoặc thay đổi ánh sáng đột ngột.
-
Đặc trưng hình học rõ ràng: Point cloud biểu diễn hình dạng 3D của đối tượng, giúp phân biệt rõ ràng giữa các loại vật thể.
-
Khả năng kết hợp với dữ liệu khác: Point cloud có thể kết hợp hiệu quả với dữ liệu từ camera để tạo ra hệ thống nhận diện đối tượng mạnh mẽ.
Lịch sử Deep Learning cho phát hiện đối tượng 3D
Trong lĩnh vực phát hiện đối tượng 3D (3D Object Detection), các phương pháp deep learning phát triển theo hai hướng chính:
1. Phương pháp dựa trên Point-based
Các mô hình như PointNet, PointNet++ xử lý trực tiếp trên dữ liệu điểm, tận dụng tính bất biến hoán vị (permutation invariance) của point cloud. Tuy nhiên, phương pháp này gặp các thách thức:
- Xử lý chậm với số lượng điểm lớn
- Khó khăn trong việc trích xuất thông tin cục bộ
- Tốn nhiều tài nguyên tính toán Lợi ích duy nhất của phương pháp này là deep learning network không bị phụ thuộc vào số lượng point đầu vào, có nghĩa rằng dữ liệu không cần tiền xử lý, mạng có thể học với số lượng điểm thay đổi.
2. Phương pháp dựa trên Voxel-based
Các phương pháp dựa trên Voxel-based xuất phát từ ý tuởng tương tự như 2D Object Detection. Sử dụng mạng CNN để trượt qua các vùng recceiptive filed, trích xuất đặc trưng cục bộ từ những vùng này, tạo ra những feature map với kích thước nhỏ hơn và có chiều sâu hơn. Các phương pháp sử dụng voxel-based tận dụng được concept khả năng tính toán của mạng CNN khi có thể trích xuất đặc trưng rất tốt cho các bài toán object detection, segmentation. Tuy nhiên, dữ liệu đầu vào point cloud
Tại sao cần Voxelization cho Point cloud
Voxelization là quá trình chuyển đổi point cloud thành lưới 3D gồm các voxel (khối 3D, tương tự như pixel trong không gian 2D). Đối với 1 ảnh 2D, một cách tự nhiên chúng ta đã biết trước độ rộng và cao (W, H) của một ảnh, cũng như đơn vị nhỏ nhất (unit) là 1 pixel. Thông tin này là bắt buộc cho một đầu vào dữ liệu để 1 kernel trong 2D convolution có thể biết chúng có thể “trượt” tới giới hạn nào (boundary), cũng như bước nhảy (stride) là bao nhiêu.
Về cơ bản, dữ liệu ảnh 2D là có cấu trúc (về mặt không gian), khi đã được định nghĩa trước về giới hạn và bước nhảy.
Ngược lại đối với point cloud thu thập từ lidar, đây là một dạng dữ liệu phi cấu trúc (về mặt không gian). Ví dụ, một điểm trong không gian được lưu dưới tọa độ (50.00012, 12.9230940234, 3.0) -> trong hệ tọa độ Decars tương ứng x =50.00012 meters, y =12.9230940234, z= 3.0 , điêm tiếp theo (50.1, 12.3, 3),… vậy đâu là đơn vị nhỏ nhất để 1 kernel có thể trượt? 1cm, 1mm hay 1nm.
Điều này giải thích cho việc lidar point cloud là một dạng dữ liệu phi cấu trúc trong không gian. Điều này khiến chúng ta không thể đưa dữ liệu này vào mạng tích chập
Tóm lại, lợi ích của voxelization
-
Cấu trúc dữ liệu có quy tắc: Voxel tạo ra cấu trúc lưới đồng nhất phù hợp với các mạng CNN hiện đại.
-
Hiệu quả tính toán: Giảm đáng kể số lượng điểm cần xử lý bằng cách gom nhóm các điểm trong cùng một voxel.
-
Trích xuất đặc trưng không gian tốt hơn: Dễ dàng nắm bắt thông tin cục bộ và quan hệ không gian giữa các vùng.
-
Xử lý song song hiệu quả: Cấu trúc lưới voxel tương thích với GPU, cho phép tính toán song song.
-
Biểu diễn đa tỷ lệ: Có thể dễ dàng tạo ra biểu diễn đa tỷ lệ (multi-scale) bằng cách thay đổi kích thước voxel.
Quy trình Voxelization
Hãy cùng phân tích quy trình voxelization từ code đã cung cấp:
# Định nghĩa vùng không gian cần xử lý và kích thước voxel
PC_RANGE = [-50.0, -50.0, -3.0, 50.0, 50.0, 3.0] # x_min, y_min, z_min, x_max, y_max, z_max
VOXEL_SIZE = [5.0, 5.0, 5.0] # kích thước voxel theo 3 trục x, y, z
Quy trình voxelization chính bao gồm các bước:
-
Định nghĩa không gian: Xác định vùng không gian cần xử lý (PC_RANGE) và kích thước voxel (VOXEL_SIZE).
- Chuyển đổi tọa độ: Chuyển tọa độ điểm từ không gian thực sang chỉ số voxel:
non_empty_voxel_indices = np.floor((points[:, :3] - PC_RANGE[:3]) / VOXEL_SIZE).astype(np.int32) - Gom nhóm điểm: Gom các điểm vào voxel tương ứng:
voxel_dict = defaultdict(list) for i in range(N): key = tuple(non_empty_voxel_indices[i]) voxel_dict[key].append(points[i]) - Trích xuất đặc trưng: Tính toán đặc trưng cho mỗi voxel dựa trên các điểm bên trong.
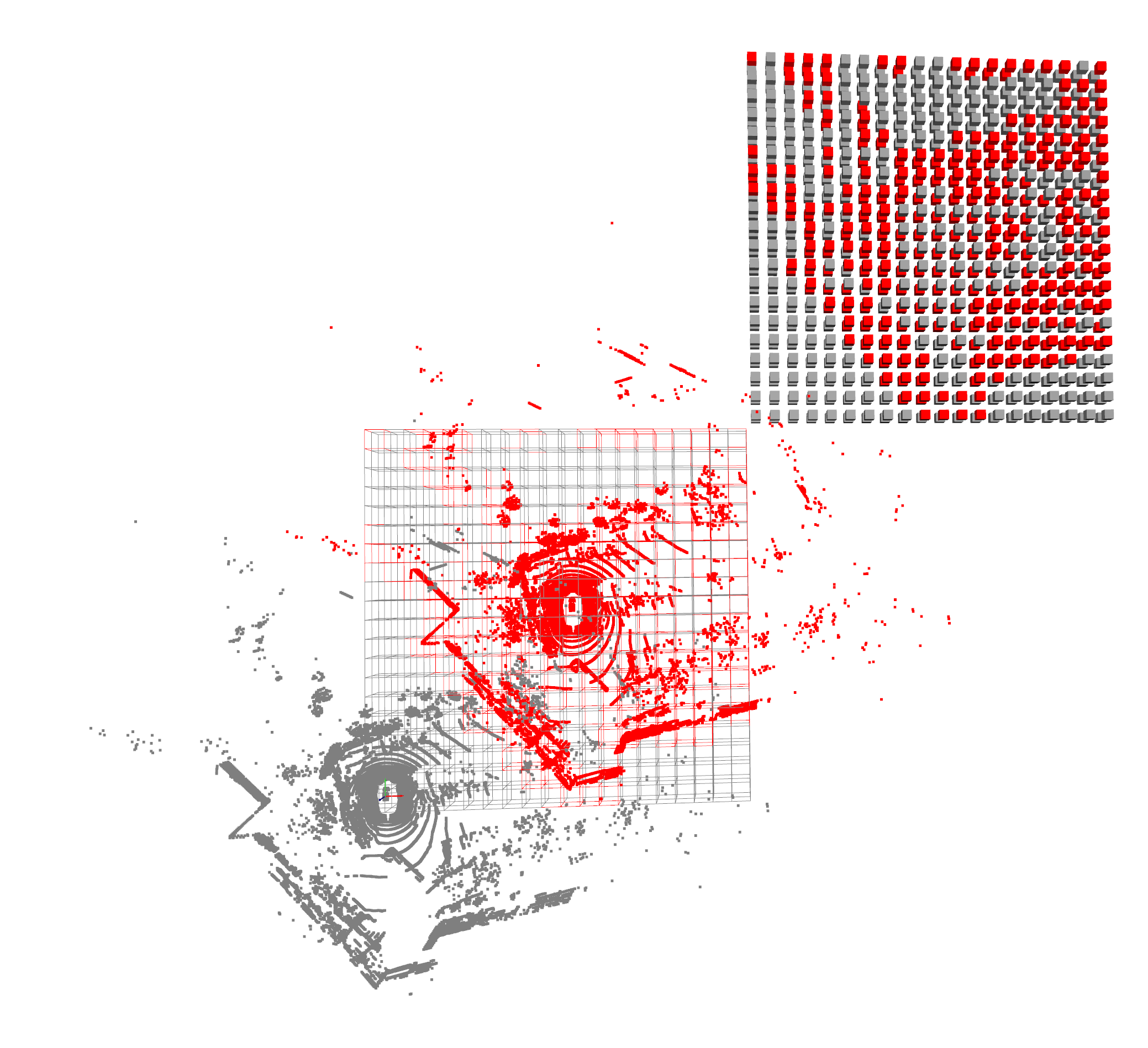
Ứng dụng Voxelization trong mô hình phát hiện đối tượng 3D
Voxelization là nền tảng cho nhiều mô hình phát hiện đối tượng 3D hiện đại:
-
VoxelNet: Mô hình tiên phong sử dụng voxel, tích hợp giai đoạn voxelization và mạng phát hiện đối tượng 3D trong một kiến trúc end-to-end.
-
SECOND (Sparsely Embedded CONvolutional Detection): Cải tiến VoxelNet bằng cách sử dụng tích chập thưa (sparse convolution) để tăng hiệu suất tính toán.
-
PointPillars: Đơn giản hóa voxel thành “pillars” (các cột theo chiều z), giảm thiểu độ phức tạp tính toán nhưng vẫn duy trì hiệu suất tốt.
-
CenterPoint: Kết hợp voxelization với phương pháp phát hiện tâm đối tượng, cải thiện độ chính xác trong bài toán theo dõi đối tượng 3D.
Thử nghiệm trực quan
Code mẫu bao gồm phần trực quan hóa quá trình voxelization, giúp hiểu rõ hơn về cách point cloud được chuyển đổi:
def visualize_voxel_with_points(points, voxel_features, coors, sparse_shape):
geometry_list = []
# Hiển thị cả point cloud gốc và biểu diễn voxel
# ...
# Vẽ point cloud gốc
raw_point_cloud = o3d.geometry.PointCloud()
raw_point_cloud.points = o3d.utility.Vector3dVector(points[:, :3])
raw_point_cloud.colors = o3d.utility.Vector3dVector([[0.5, 0.5, 0.5] for _ in range(points.shape[0])])
geometry_list.append(raw_point_cloud)
# Vẽ các voxel
for i,center in enumerate(all_voxel_center):
voxel_grid = draw_bounding_box(center, all_colors[i])
geometry_list.append(voxel_grid)
Kết quả trực quan hóa cho thấy cách các điểm được gom nhóm thành voxel, tạo ra biểu diễn có cấu trúc của môi trường 3D.
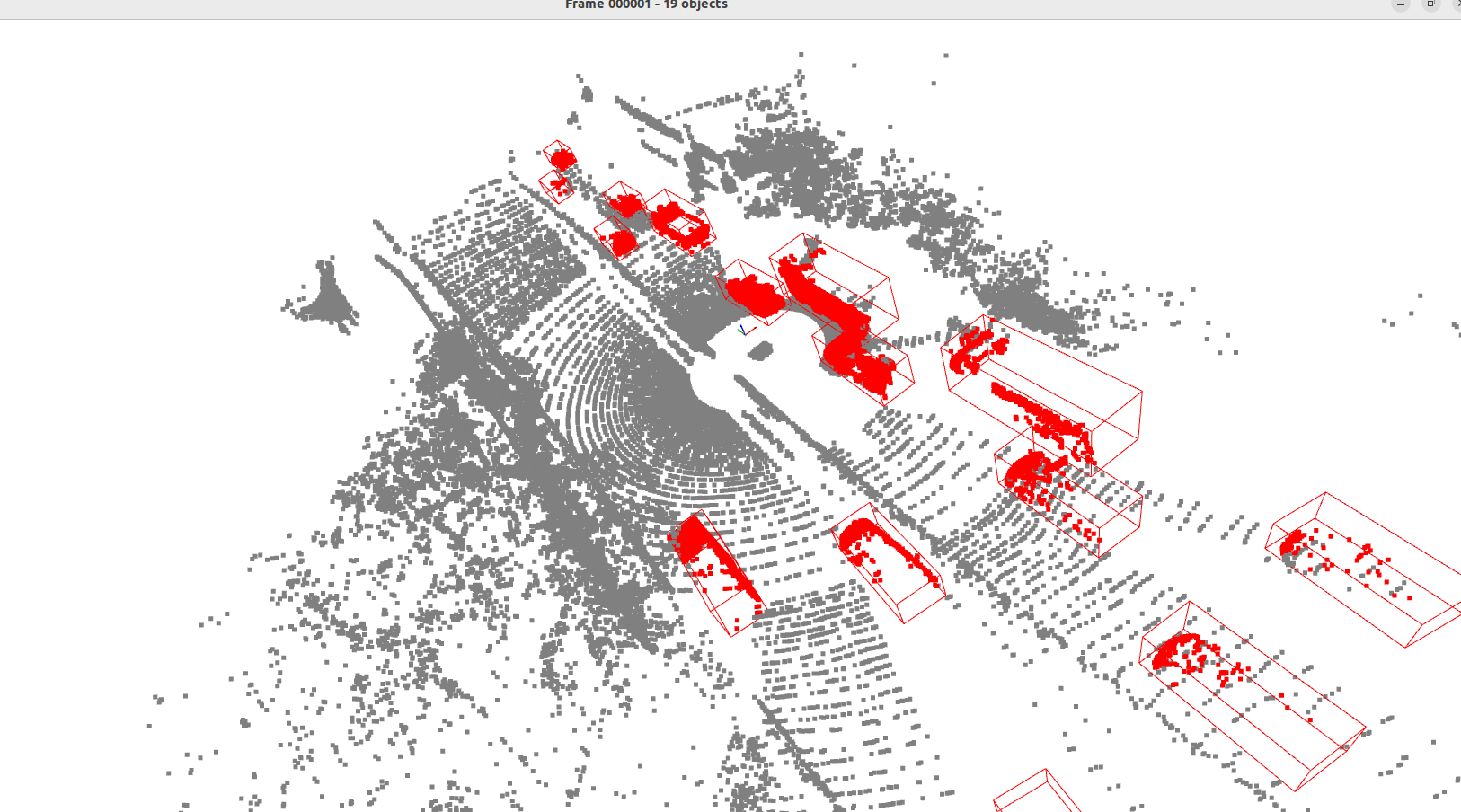
Kết luận
Voxelization là kỹ thuật quan trọng trong việc xử lý dữ liệu point cloud cho xe tự lái, đặc biệt trong bài toán phát hiện đối tượng 3D. Bằng cách chuyển đổi dữ liệu point cloud không có cấu trúc thành lưới voxel có cấu trúc, voxelization cho phép áp dụng hiệu quả các kiến trúc deep learning như CNN, giúp cải thiện cả hiệu suất tính toán và độ chính xác.
Trong tương lai, với sự phát triển của phần cứng và thuật toán, chúng ta có thể kỳ vọng vào các phương pháp voxelization tiên tiến hơn, tạo ra các biểu diễn thưa và đa tỷ lệ, mở ra khả năng phát hiện đối tượng 3D nhanh hơn và chính xác hơn cho các ứng dụng xe tự lái.